Developing Async Sense in JavaScript
This series of article will take a dive into the main asynchronous patterns in JavaScript, comparing some of the tradeoffs of callbacks, promises, and async/await, and demonstrating how each pattern builds on top of the previous.
We’ll try to demystify concepts like the Event Loop, Single-threaded, Run to Completion and Non-Blocking.
We’ll see how we can deal with things happening “at the same time” and maybe even eliminate time as a concern.
Why?
Managing asynchronous code in JavaScript isn’t intuitive.
First attempt at async code:

On StackOverflow, the following question is one of the most voted on and most viewed question in all categories:
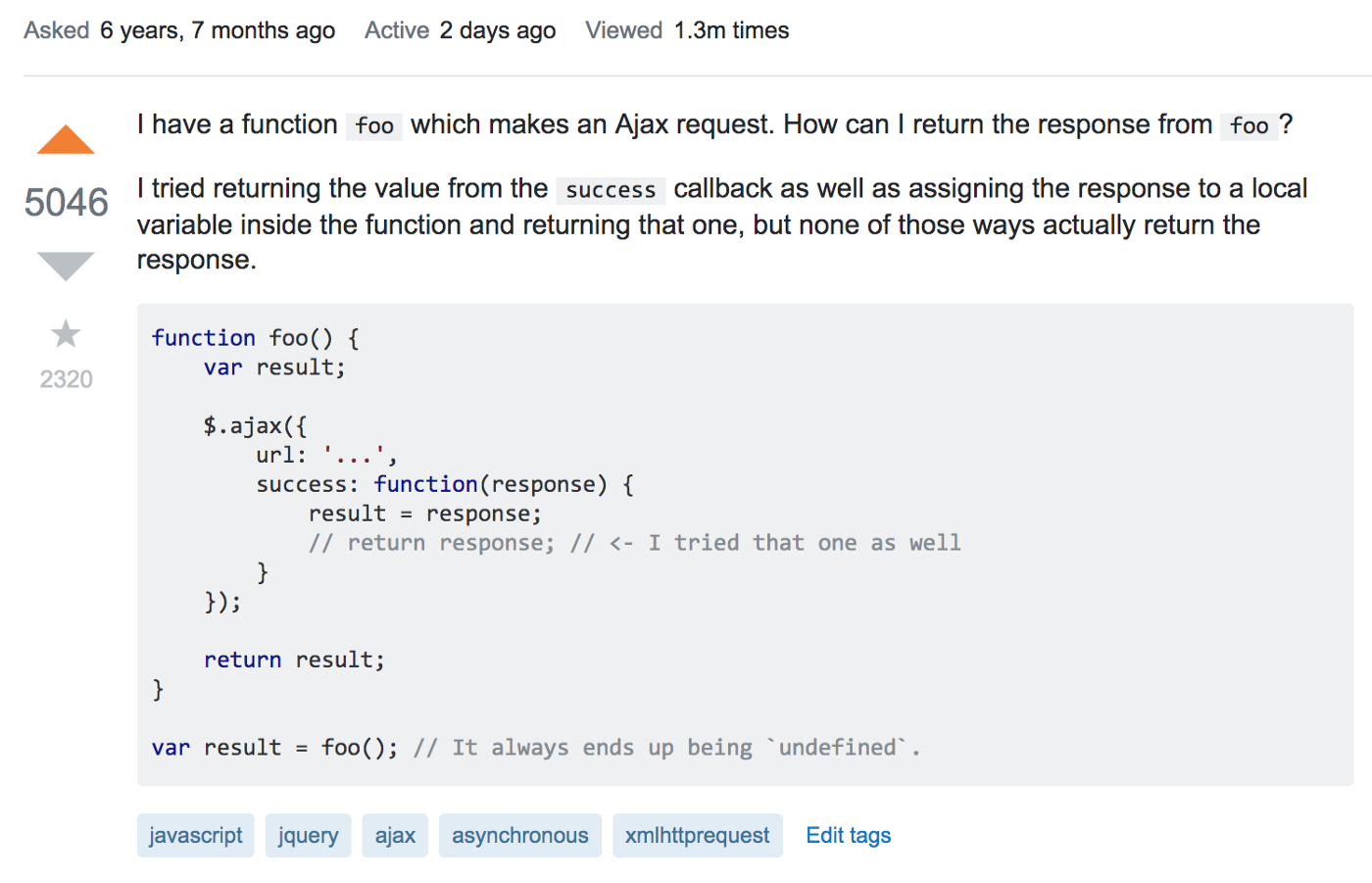
If you’re not new to the language, it can be easy to forget how confusing this code really is. It takes some time getting used to the visual jumps through the non-linear async flows to naturally recognize when and where the data will arrive.
But let’s not jump ahead of ourselves.
Before we get into the weeds of asynchronicity in JavaScript, let’s first clarify what we usually mean when we call a piece of code async.
What is Async?
One way to think about the difference between sync and async is:
- Synchronous means things are happening chronologically one after the other.
- Asynchronous means things are happening chronologically independent of one another.
When you execute a task synchronously, you wait for it to finish before moving on to another task. When you execute a task asynchronously, you can move on to another task before the prior task finishes.
Sync: Doing 3 tasks

Async: Doing 3 tasks

Note: Async code is not the same as concurrent code. Concurrent tasks are intertwined in terms of time while sync or async tasks are blocking (need to wait before proceed) or non-blocking operation (don’t need to wait before proceeding).
Concurrent computing is a form of computing in which several computations are executed during overlapping time periods — concurrently — instead of sequentially (one completing before the next starts).
Threads
The most common construct across programming languages that allows us to execute concurrent code is something called a thread.
At a bare minimum, a thread can be thought of as an interruptible execution of a piece of code. An interruptible task is a task that can be performed in chunks (paused and continued).
Those chunks could run one after the other, we could do other tasks in between each chunk, we could run the chunks in parallel etc.
Parallelism is just one form of concurrent execution (and is hardware dependent! The only way we could achieve true parallelism is by running our code on multi-core machines).
Here’s a quick example to demonstrate how concurrent execution doesn’t have to be parallel.
Let’s say we have to do the following two tasks:
- Call ATT and cancel our subscription
- Write a blog post
If we were to do these tasks concurrently, it would go something like this:
- Call ATT and get put on hold
- Start writing our blog post
- Once the operator answers, we stop writing and cancel our subscription
- Once we hang up, we finish up our blog post
Both tasks were done concurrently, interleaved with each other, but weren’t actually done in parallel. We were always doing one task at a time.
Note: This is usually called time-slicing. On single-core machines, the OS splits the execution of threads into small chunks which still run in series but interchange fast enough to deceive our senses into appearing simultaneous.
In a truly parallel scenario, we’d get our roommate to call ATT while we work on our blog post and both tasks would get done completely independently.
Note: If you’re interested in learning about parallelism and concurrency, I suggest starting with this awesome talk by Rob Pike.
Concurrency increases complexity
Threads allow us to execute any piece of code, including the same one, multiple-times concurrently. This leads to a non-trivial increase in code complexity, particularly when the concurrent execution interacts with a shared resource.
When multiple threads are operating on a shared resource, they end up in a race of who gets to the shared data first. This issue is usually called the race-condition. If not managed properly, it can easily lead to data corruption.


To further demonstrate this complexity, let’s assume we have the following snippet that is executed in two threads around the same time where both threads are operating on the same array:
arr.push('a')
if (arr.length == 1) {
arr.push('b')
}How many outcomes can this code have? Is it even easy to tell? What can arr contain when this snippet is executed by both threads?
Well, let’s see. How many unique statements do we have?
Note: in statement 2, we combine checking the length of arr, comparing to 1 and evaluating to a boolean into a single statement for the sake of brevity. The actual split into atomic operations would be language-specific.
These 3 ordered statements can be executed by any of the 2 threads, with overlap.
Let’s see a few of the possibilities:

Even without calculating all possibilities we can immediately recognize that the output of this code is difficult to predict. Without some safety mechanisms, multi-threaded code would be practically impossible to tame.
Extra: Another common problem arises when two or more threads are permanently waiting on one another in order to proceed execution. This leads to a “lock” in execution called a deadlock.
A common solution to race conditions is to use Mutual Exclusion principles involving data structures like a lock (mutex), a semaphore, or a monitor to protect the shared resource (critical section). Any of these data structures are fundamentally a locking mechanism (sometimes just a variable) that is used to synchronize multiple threads to interact with the data in a specific order.
If we take our snippet from above, here’s how we can use a hypothetical lock to ensure that threads do not overlap when adding data to arr:
// lock execution to the current thread.
// Any new thread reaching this line will be queued up
// until the locking thread releases the lock
lock()
arr.push('a')
if (arr.length == 1) {
arr.push('b')
}
unlock() // free execution for the next thread
// only possible output is ['a', 'b', 'a']But how does JavaScript handle concurrency? There are no locks in the language.
On one hand, this is nice because we don’t have to worry about issues like deadlocks and concepts like mutexes that might make the code difficult to reason about. Still, there are so many things happening when our JavaScript apps run and it would be painfully slow if everything was running synchronously.
Do threads even exist in JavaScript?
JavaScript and Threads
The expression “JavaScript is single-threaded” has been abundantly shared in the JS ecosystem.
What does this actually mean?
It means that the JavaScript Event Loop is handled by a single thread.
Note: the addition of Workers allows us to achieve language level multi-threading in JS both on the web and in NodeJS but they do so in a special way where each Worker gets its own event loop.
What is the Event loop?
The Event Loop is a part of the JavaScript runtime that executes tasks scheduled on a Task Queue, one at a time. A Task Queue can be thought of as an array where we push on one end and pull from the other, in a FIFO manner. A single execution of a Task is called a Tick.
Here’s how it would look like in pseudo-code:
function eventLoop() {
// perform loop ticks, "forever"
while (true) {
var nextTask = taskQueue.getNextTask()
nextTask()
}
}Note: To complicate things a bit further, the Event Loop can actually have multiple Task Queues.
function eventLoop() {
// perform loop ticks, "forever"
while (true) {
var tastQueue = selectTaskQueue()
var nextTask = taskQueue.getNextTask()
nextTask()
}
}For the purposes of this article, it’s enough to know that Tasks can be put into the Event Loop from multiple places and in an unpredictable order that is mostly out of the control of the programmer.
A Task can be practically anything happening in a JavaScript application. A typical example would be a callback given to setTimeout that should be executed in N milliseconds. In the browser, a Task can be a repaint-job, an ajax response callback from the network or user input. In NodeJS it can be a network request callback or an I/O operation.
Note: Tasks may also schedule other tasks.
All of these various processes in and around JavaScript work together to schedule tasks in the Event Loop, which then executes them in order.
Note: The actual order of tasks depends on when they are created, what type of task they are (micro vs macro), who created them, and how important they are.
We can think of the Event Loop as a single-seat rollercoaster ride in an amusement park that has many lines of people waiting to go on the ride, one by one. When you get to go depends on when you got in a line, how important you are or if a friend saved you a spot but nevertheless only one person at a time will be able to partake.
Under the hood, many of these operations actually do get performed in separate threads. In the browser, systems such as the DOM parsing, the CSS Layout and Styling, or the Network typically run in separate threads. NodeJS automatically offloads many I/O (such as file-system reading and writing) and CPU intensive operations (for example cryptographic ops) into the Worker thread pool. All of these operations potentially working in separate threads still schedule Tasks within the same single-threaded Event Loop.
The JS Engine that parses and executes our code (for example V8) runs on the main thread and has the highest priority in the Task Queue. This means that the execution of JavaScript code will be prioritized over Tasks dealing with network responses or DOM updates in the browser or I/O operations in NodeJS.
The flip-side of this behavior is that JS code has a special property to it called Run-to-Completion. Function code in JavaScript is atomic. Once a function starts it will finish.
Note: Generators and async/await break this semantic because they allow a function to run partially.
This also means that we have a single Call Stack. A Call Stack is a data structure that keeps track of the point to which each active function should return control to when it finishes executing (in LIFO order). By having a single Call Stack, we are allowed to only have a single flow through our code.
Here’s an example of how the Call Stack works. Notice how we keep the function one on the Call Stack until all the code within it, including the nested function call to two, is finished executing.

On top of having a single Call Stack, we are also limited in how much information we can add to it.
function recurseForever() {
recurseForever()
}
recurseForever()
// outputs
// Uncaught RangeError: Maximum call stack size exceededAttempting to pass the limit of the Call Stack is called a stack overflow.
Tip: we can do a little try/catch trick to find out the exact size of the Call Stack.
// Credit: http://2ality.com/2014/04/call-stack-size.html
function computeMaxCallStackSize() {
try {
return 1 + computeMaxCallStackSize()
} catch (e) {
return 1
}
}Another perspective to all of this is that, while synchronous code is running, no asynchronous code can run. Async code can run once the Call Stack is empty.
In fact, async code is essentially just a synchronous piece of code that is scheduled to run at a later point.
This single-threadiness of Task execution is why, if the Rendering Engine in the browser wants to repaint but JS is still running, we get jerkiness. If a function takes too long to complete, the web application is unable to process user interactions (like click or scroll).
A somewhat famous example is the innerHTML property on a DOM Element. Parsing the string set by this property is actually a synchronous operation and runs on the main thread, blocking any interactions until it finishes.
Try clicking anywhere in this Pen while the loop is running.
Note: when you run the Pen, your UI will get blocked for a short period of time.
Why does this matter?
Good UX === Non-Blocking
An analogy that comes to mind is the customer service industry. When we call a company to talk to customer service, we are usually put in an on-hold queue and are blocked until a representative is free to reach out. Being on hold sucks. It is inefficient. A much better customer service system would be one where we schedule a call back at our earliest convenience.
Perhaps there’s a construct that JavaScript provides us to deal with async code in a non-blocking manner?
Next up: Developing Async Sense Part II: Callbacks